Beyond ChatGPT: Benchmarking the Behavior of Top AI Chatbots
As Large Language Models (LLMs) take on crucial decision-making roles, understanding their hidden behavioral patterns is critical.
A recent study had focused on OpenAI's ChatGPT variations, but it remained unclear whether those findings extended to other major players. This new comprehensive analysis benchmarks the decision-making strategies of five leading LLM families (OpenAI GPT, Meta Llama, Google Gemini, Anthropic Claude, and Mistral) as they navigate classic behavioral economics games.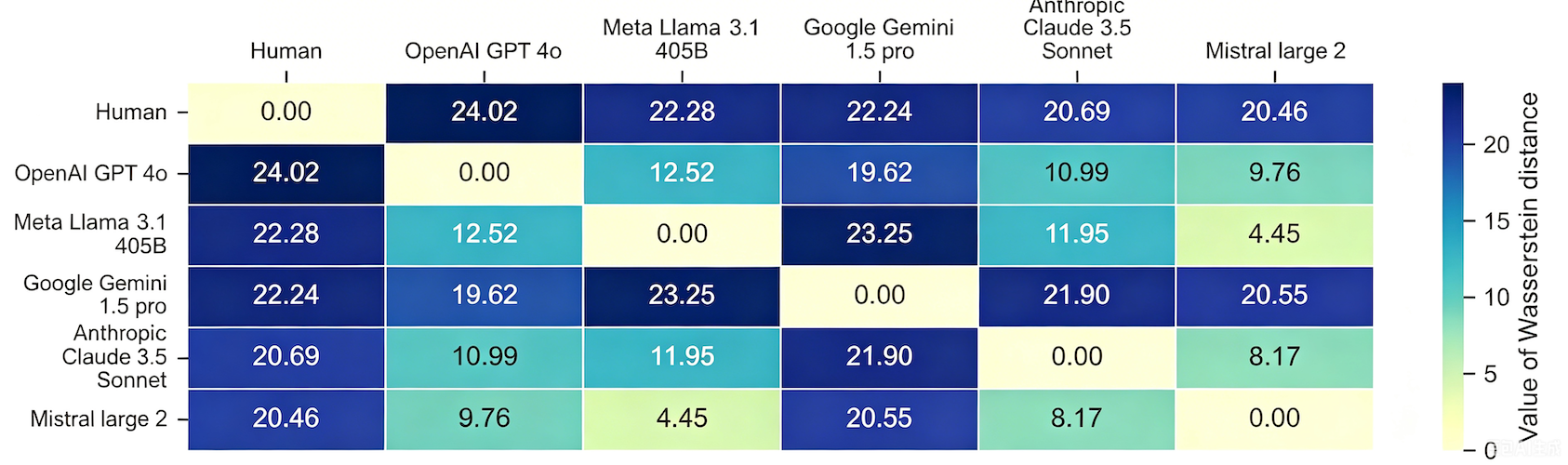
The Behavioral Benchmark
The researchers used a series of classic behavioral economics games designed to test nuanced, human-like judgment. These games evaluate key traits, including:
Fairness
Trust
Risk Aversion
Altruism
Cooperation
By systematically evaluating 50 independent responses from the flagship model of each chatbot family across these games, the study aimed to profile and differentiate these AI systems.
Key Findings on AI Behavior
The analysis uncovered significant commonalities and distinct differences in how these top LLMs behave:
Concentrated Decisions: All tested chatbots successfully capture specific human behavior modes, but their decision distributions are often highly concentrated compared to the wide spread of human choices.
Emphasis on Fairness: Compared to humans, AI chatbots consistently place a greater emphasis on maximizing fairness in their payoff preferences.
Inconsistencies: The models may exhibit inconsistencies in their payoff preferences and strategies when transitioning between different games.
Distinct Profiles: The different AI chatbots exhibit distinct behavioral patterns, allowing the behavioral benchmark to effectively profile and differentiate them.
Why This Matters
These findings provide valuable insights into the strategic preferences of each LLM. Understanding these behavioral nuances is essential for optimizing AI performance and ensuring its reliability and predictability, particularly as they are increasingly deployed in critical decision-making contexts across diverse applications. This research significantly advances the understanding of AI behavioral science.